The picture, which was uploaded to photo-sharing site Flickr in 2013, isn't just adorable; with a bunch of different faces in various positions, it's also useful for training facial-recognition systems, which use artificial intelligence to identify people in photos and videos. It was among a million images that IBM harnessed for a new project that aims to help researchers study fairness and accuracy in facial recognition, called Diversity in Faces.
The woman who shot the image, a librarian in rural Vermont named Jessamyn West, was surprised and angry when she found out the photo was being used by IBM. She had uploaded it to Flickr with a Creative Commons license that lets others use the photo. But something about not knowing that this image, along with other Creative Commons-licensed pictures she took — a self-portrait and about a dozen other shots — were included in a facial-recognition dataset bothered her.
"I think if anybody had asked at all, I would have had a different feeling," she said.
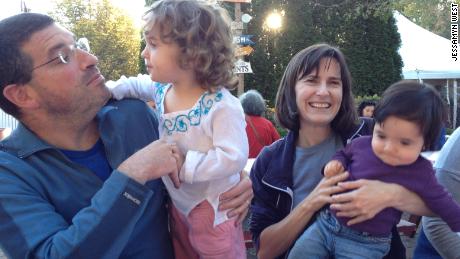
For years researchers have turned to the internet to collect and annotate photos of all kinds of objects — including many, many faces — in hopes of making computers better understand the world around them. This frequently means using Creative Commons-licensed images from Flickr, pulling images from Google Image search, snagging them from public Instagram accounts or other methods (some legitimate, some perhaps not). The resulting datasets are typically meant for academic work, like training or testing a facial-recognition algorithm. But increasingly facial recognition is moving out of the labs and into the domain of big business, as companies such as Microsoft, Amazon, Facebook, and Google stake their futures on AI.
And as consumers are increasingly aware of the power of the data they leave like breadcrumbs across the internet, facial-recognition datasets are becoming a flash point for worries about privacy and a future where surveillance may be more commonplace.
As a result, some researchers say they're now rethinking the Wild West atmosphere that pervades the face-gathering status quo, and what it means to give consent for the use of an image of yourself (or of someone else that you photographed) in a world where we constantly share our lives online.
Where the faces come from
Facial recognition has improved dramatically in recent years due to the popularity of a powerful form of machine learning called deep learning. In a typical system, faces are scanned (from still images, videos, or a live stream), and their features analyzed and then compared with labeled faces in a database.
The technology is being used to fight human trafficking and help people speed through airport security; it's also being used for surveillance by law enforcement groups, at concerts, at sports events, and elsewhere.

Yet there are still accuracy issues. Researchers are increasingly concerned about bias in AI systems, which is evident in, say, how well the tech can do things like correctly recognize people of color and women. One reason for this issue is that the datasets used to train the software may be disproportionately male and white; IBM believes Diversity in Faces is more balanced than previous datasets.
Diversity is important for training, but so is the sheer amount of data used. Facial recognition systems may be trained and tested on thousands or even millions of faces.
The particular images that Diversity in Faces draws on have been available to researchers for years. The dataset includes URLs linking to photos, all pulled from a public list of 100 million Flickr photos that researchers from Flickr and Yahoo (Flickr's owner at the time; it's now owned by SmugMug) released in 2014. Known as YFCC100M, it has aided all kinds of scientific projects, such as estimating where photos and videos were taken without using geographic coordinates.
IBM is just one among a slew of companies, research institutions, and individuals that have compiled datasets for facial recognition — some of which include actual images, some of which, like IBM's, have image links. Occasionally, these datasets are made by photographing models. But the internet has long been an irresistible resource.

Often, such datasets are shared with the stipulation that they be used for non-commercial applications, such as research, but plenty of these datasets can be freely downloaded from websites such as Github, as CNN Business found.
David A. Shamma, who helped put together the Flickr dataset when he was director of research at Yahoo Labs, said that for years academics working on computer vision or object recognition were just trying to scrape data wherever they could get it.
"It was just an academic process where people would often say, 'No harm, no foul,'" he said.
By releasing the big Flickr dataset, Shamma, now a senior research scientist at FX Palo Alto Laboratory, felt he and his colleagues had an opportunity to hand a big, licensed pile of images to researchers so they could build upon it.

Those images had been uploaded to Flickr both by regular people like West, and by pros, all with Creative Commons licenses. These are special kinds of copyright licenses that clearly state the terms under which such images and videos can be used and shared by others, though you may not be thrilled about the specific ways they are used.
Creative Commons licenses were first released in 2002, and Flickr in particular has been around since 2004 — way before the current AI boom.
While researchers freely use images on sites like Flickr, they also acknowledge that many people posting these photos may be surprised to learn they can be used to train or test AI.
"I think people expect it, but when you confront them with exactly what it's being used for, they won't expect it," Shamma said.
Changing expectations
It took West by surprise. After reading an NBC News story in March about IBM's dataset that included a tool NBC made to look up whether a Flickr user's photos were included in it, she typed in her Flickr username: iamthebestartist. West was upset when she realized the photo she took of her junior-high friend's family and numerous other photos were part of it. She thinks AI will be helpful in the future, but she's concerned about her photos being used to train it without her knowledge.
Angry posts on Twitter show plenty of other people are also unhappy to discover the images they shared online, often long ago, are becoming fair game for training facial-recognition and other kinds of AI.
West asked IBM to remove her images from the dataset, which can only be done by emailing the company. She also had to authorize IBM to use her Flickr ID so the company could find and remove each of the photos.
IBM told CNN Business that it is "committed to the privacy rights of individuals" and that anyone who is included in the dataset can opt out at any time. It's not offering a tool of its own to find out if specific images are linked in the dataset, though, so people have to look it up via the one built by NBC.
Meanwhile, researchers at graphics chip maker Nvidia are looking at IBM's experience and thinking about how to change their own practices.

In March, Nvidia released an online tool that lets people see if their images are included in the dataset used to train StyleGAN, an AI system unveiled in February that is adept at coming up with some of the most realistic-looking faces of nonexistent people that machines have produced thus far. That dataset contains 70,000 high-quality, Creative Commons-licensed Flickr images.
The tool came after NBC published its story, but David Luebke, Nvidia's vice president of graphics research, said it was already in the works for some time.
"We were thinking forward to what this would look like as people become more aware of this," he said. "If some people have objections, we want to make sure we're respectful of that."
The company also included a list of steps users can take if they want their photo removed from the dataset, and if they'd like to avoid having it used for future computer-vision research. These suggestions include making the photo private, changing the license attached to it, or even adding a tag to the photo — a word or phrase associated with the image that's searchable on Flickr — that says "no_cv" to show they don't want it to be used for computer-vision research.
"I think a lot of people either don't care or would actively want their photos to go into something like StyleGAN," Luebke said. "But if you don't, there should be a way to opt out."

Some researchers believe a good way to give people more control over how their images are used may be via a license that lets them determine clearly whether individual images they post online can be used for computer-vision or AI.
This is unlikely to come from Creative Commons, though. The nonprofit's licenses don't limit or prohibit any use of images for the development of any sort of AI, as long as the terms attached to a work are followed.
"The licenses are not designed as a tool to protect privacy or protect research ethics," said Creative Commons CEO Ryan Merkley.
Waiting for legislative help
Artificial intelligence has been rolled out so swiftly in recent years that regulations have barely begun to be formulated, let alone implemented. And when it comes to gathering and using images for facial recognition, companies and researchers aren't legally obligated to tell people much of anything.
There are no such federal rules related to how the technology can be built or used. A bit more has happened at the state level: Illinois, for example, has a law that requires companies get consent from customers before collecting biometric information. And the state senate in Amazon and Microsoft's home state of Washington recently passed a bill that limits the use of facial recognition. That bill still has to pass the state's house of representatives.

Merkley and others think legislation concerning how data is gathered for training and testing this kind of technology should be considered. This could happen in the not-so-distant future: in March, a Senate bill was introduced that would force companies to get consent from consumers before collecting and sharing identifying data. It would also require companies to conduct outside testing to ensure algorithms are fair before they're implemented, and let people know when facial-recognition technology is in use.
Even in the absence of strict legal boundaries for using images of people to train AI systems, there's an ethical boundary companies and research groups should pass, said Jeremy Gillula, technology policy director for digital rights group the Electronic Frontier Foundation.
In his view, that means getting explicit consent from people whose faces are in those images. Sometimes that will be hard, he said, but that's a reality companies should have to face.
"I definitely think it matters," Gillula said. "I think it matters to the people whose images are being used for purposes they hadn't imagined they'd be used for."
Bagikan Berita Ini














0 Response to "If your image is online, it might be training facial-recognition AI"
Post a Comment